Pandas小技巧,給Excel添加一列,處理成績數字的等級
給大家分享一個處理的非常小的技巧知識點。
怎樣給一個添加一列,這一列是根據其它列的數字計算出來的。
問題定義
問題是這樣的一個輸入的文件:
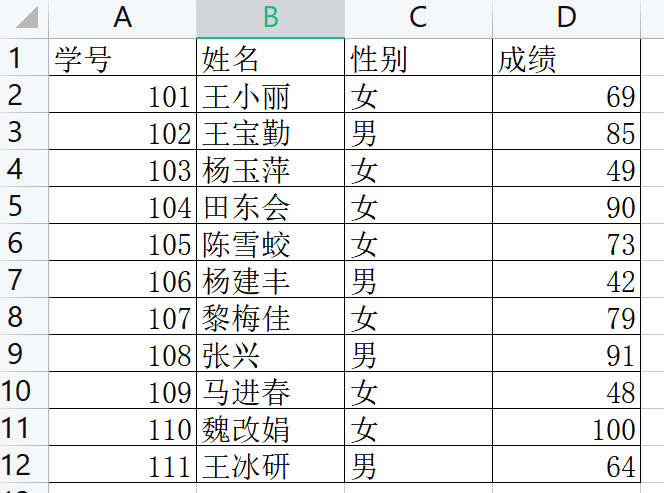
學號?姓名?性別?成績
101?王小麗?女?69
102?王寶勤?男?85
103?楊玉萍?女?49
104?田東會?女?90
105?陳雪蛟?女?73
106?楊建豐?男?42
107?黎梅佳?女?79
108?張興?男?91
109?馬進春?女?48
110?魏改娟?女?100
111?王冰研?男?64
其中成績是一列數字,那么怎樣給成績劃分等級?如下是劃分等級的計算規則:
60分以下為E級
60~69分為D級
70~79分為C級
80~89分為B級
90分以上為A級
如下進行處理,簡單起見,我挨個進行解釋:
1. 導入模塊,讀取文件
import?pandas?as?pd
df?=?pd.read_excel("成績表.xlsx",?sheet_name=0)
第一句導入了模塊,這是的數據處理和統計分析的重要模塊。
pd.可以讀取的文件,=0意思是讀取第一個表格的數據。
這個df非常重要,表達的就是一個表格數據。
2. 編寫自己的根據成績劃分等級的函數
def?grade_to_level(grade):
????"""
????grade是成績
????把這個Excel中的成績,劃分為A- E這五個分數區間。
????60分以下為E級、60~69分為D級、
??? 70~79分為C級、80~89分為B級、90分以上為A級。
????"""
????if?grade?>=?90:
????????return?'A'
????elif?grade?>=?80:
????????return?'B'
????elif?grade?>=?70:
????????return?'C'
????elif?grade?>=?60:
????????return?'D'
????else:
????????return?'E'
這個函數有個特點,輸入的參數是,其實就是一個數字,而這個數字,是表格的“數字”這一列的每個值。
而這個函數的返回,就是這個數字劃分后的等級,是5個字符串,A~E
注意excel怎么在一列數字前補零,這個函數的輸入是單個數字excel怎么在一列數字前補零,輸出是單個字符串。這個字符串將成為新列的每個值。
3. 給的數據表df添加一個新列
df['等級']?=?df['成績'].apply(grade_to_level)
其中df['成績']意思是訪問了當前的“成績”這一列,這是一列數據,里面有很多數字。
df['成績'].是在這個成績列上調用的函數,而這個函數很神奇,會調用我們第2步驟自己寫的 函數。
這行代碼執行的邏輯excel怎么在一列數字前補零,是取出成績列的每個成績數字,傳給函數的每個參數,得到結果是等級字符串。
而這些等級字符串串聯在一起,形成了一個新的列。
這個新列和成績列的行數一模一樣相等,同時每個等級和每個成績是一一對應的關系。
而等式左側的df['等級']則接收了這個結果的列。
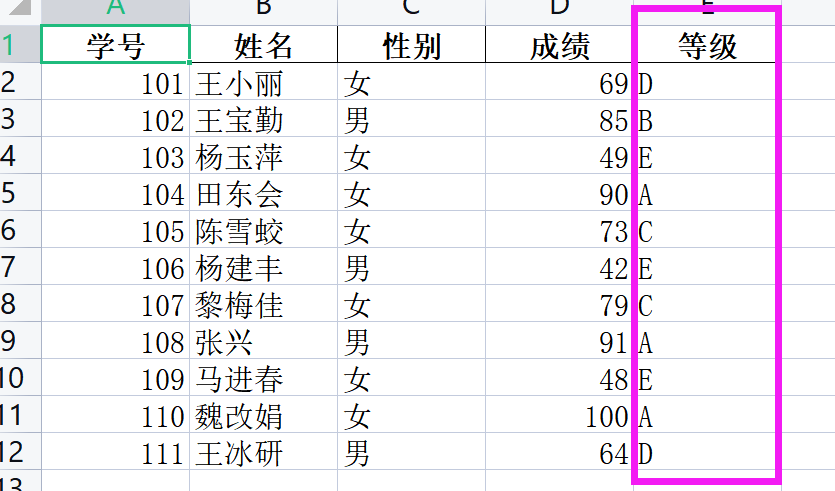
最終這行代碼實現了,成績列被一一轉換成了等級列。
4. 輸出成結果文件
df.to_excel("成績表分類后.xlsx",?index=False)
這一列,將新的處理后的df,輸出成一個文件,名字是 成績表分類后.xlsx
如果不加=這個參數,那么輸出的結果表格中,會多一列,里面是從0開始到1到一直遞增的數字,無意義。所以一般都加上這個參數。
5. 最后的效果
輸入文件截圖:
輸出文件結果:
6. 數據和代碼地址
代碼地址,自己粘貼到瀏覽器訪問:
%E7%BB%99%E6%88%90%E7%BB%A9%E5%88%86%E7%BA%A7%E5%88%AB
免責聲明:本文系轉載,版權歸原作者所有;旨在傳遞信息,不代表本站的觀點和立場和對其真實性負責。如需轉載,請聯系原作者。如果來源標注有誤或侵犯了您的合法權益或者其他問題不想在本站發布,來信即刪。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。